
Kommentar von Markus Schmitt, Data Revenue Ist es Zeit, Matplotlib und Pandas zu ersetzen?
23.09.2020
Autor / Redakteur: Markus Schmitt / Nico Litzel
Programmierer haben große Freude daran, verschiedene Software-Bibliotheken gegenüberzustellen. Tensorflow vs. Pytorch? Vim vs. Emacs? Python vs. R? Geht man von einer Art globalem Wettbewerb aus, in dem Software nach Beliebtheit miteinander konkurriert, stellen Pandas und Matplotlib die etabliertesten Akteure im Python-Data-Science-Bereich dar. Sie gehören zu den ältesten und am meist verbreiteten Bibliotheken für Data Wrangling und Visualisierungen. Innerhalb dieses Wettbewerbs gibt es jedoch auch interessante Konkurrenten.
Firmen zum Thema
Im Bereich Data Wrangling bieten Bibliotheken wie Dask, Vaex und Modin einige Vorteile gegenüber Pandas, wobei sie noch weniger ausgereift sind. Gleichermaßen konkurrieren Bokeh und Seaborn (neben vielen anderen) mit Matplotlib in der umfangreichen Python-Visualisierungslandschaft, da sie einfachere APIs, schönere Standardeinstellungen und moderne Funktionen bieten – etwa Interaktivität.
In diesem Artikel werden wir:
Einige angesagte Python-Bibliotheken beleuchten und diskutieren, warum sie für Data Scientists und Machine-Learning-Entwickler interessant sind;
sie mit Matplotlib und Pandas vergleichen und
zu dem Schluss kommen, dass „Wettbewerb“ die falsche Betrachtungsweise ist. Ein Buttermesser ist nicht besser oder schlechter als ein Brotmesser – sie erledigen schlichtweg andere Aufgaben. Ebenso hängt es in der Regel von der jeweiligen Aufgabe ab, welches Python-Tool man verwenden sollte. Oft ergänzen sich die Tools sogar gegenseitig.
Data Wrangling
Incumbent: Pandas
Warum Pandas beliebt ist: Einfachheit, Reife und Flexibilität
Probleme: Ineffizient, nicht skalierbar und oft auf einen einzigen Thread beschränkt.
Herausforderer: Dask, Modin, Vaex, und RAPIDS cuDF (detaillierter Vergleich)
Über Pandas wird viel gemeckert. Sogar der ursprüngliche Entwickler von Pandas hat vernichtende Kritik über Pandas geschrieben. Trotzdem ist es für viele Data Scientists ein unentbehrliches Tool, das einfache Arbeitsabläufe ermöglicht, z. B: fürs:
Einlesen von Daten aus verschiedenen Dateiformaten, einschließlich JSON und CSV;
Laden von Daten in Dataframe-Objekte;
Manipulation von Daten durch Filtern, Transformieren oder Aggregieren;
Visualisierung von Daten durch nahtlose Integration mit Matplotlib.
Da Pandas jedoch mit einem so starken Fokus auf Einfachheit und Flexibilität gebaut wurde, schneidet es in anderen Bereichen schlecht ab – insbesondere, was die Effizienz und die Skalierbarkeit auf große Datensätze betrifft.
Wie lösen andere Bibliotheken diese Probleme?
Alle Bibliotheken, die wir als Herausforderer von Pandas beleuchten, versuchen, die vertraute Oberfläche von Pandas zu erhalten, indem sie die Pandas API (komplett oder nur teilweise) implementieren. Gleichzeitig lösen sie Effizienzprobleme durch den besseren Einsatz leistungsfähigerer Hardware (Multicore-Verarbeitung, GPU-Verarbeitung oder Cluster-Computing) oder cleverer Algorithmen (wie z. B. Lazy Evaluation und Memory Mapping).
Modin
Modin ist das simpelste Tool von allen und zielt darauf ab, einen vollwertigen Ersatz für Pandas zu bieten. Wenn man bereits Pandas-Code hat, kann man schon durch Anpassen einer einzigen Zeile erhebliche Fortschritte erzielen.
import pandas as pd
Ersetzen wir einfach mit:
import modin.pandas as pd
Hierfür müssen zuerst ein paar Vorbereitungen getroffen werden. Man installiert zuerst Modin (über pip o. ä.) und dann Dask oder Ray, die Backends auf denen Modin läuft. Dann sollte alles direkt funktionieren.
Nutze Modin, wenn dein vorhandener Code stark auf Pandas angewiesen ist und du nach dem einfachsten Weg suchst, die Ausführung von Pandas zu optimieren.
Nutze Modin nicht, wenn du nach mehr Kontrolle bzgl. Skalierbarkeit suchst, oder dir Effizienz wichtiger als einfache Handhabung ist.
Vaex
Ähnlich wie Modin implementiert Vaex einen Teil von Pandas API und kann häufig als Alternative genutzt werden. Im Gegensatz zu Modin strebt Vaex jedoch keine volle Kompatibilität mit Pandas an. Stattdessen konzentriert sich Vaex hauptsächlich auf Exploration und Visualisierung. Mit Vaex kannst du Datensätze auf deinem normalen Laptop untersuchen und visualisieren, auch wenn sie größer sind als der verfügbare Speicher deines Computers. Vaex ermöglicht dies durch eine Kombination aus Lazy Evaluation (Berechnung nur dann durchführen, wenn die Ergebnisse sicher gebraucht werden) und Memory Mapping (Dateien auf Festplatten so behandeln, als ob sie im RAM geladen wären).
Nutze Vaex, wenn du einen großen Datensatz auf normaler Hardware untersuchen und visualisieren möchtest.
Nutze Vaex nicht, wenn du anspruchsvollere Datenmanipulation oder auf einen Kluster von Servern skalieren möchtest.
Dask
Modin kann zwar mit Dask betrieben werden kann, Dask stellt jedoch auch eine high-level, Pandas-ähnliche Bibliothek namens Dask.Dataframe bereit. Ähnlich wie Modin implementiert diese Bibliothek viele der Methoden von Pandas, wodurch sie in bestimmten Fällen Pandas vollständig ersetzen kann. Ähnlich wie Vaex nutzt auch Dask Lazy Evaluation, um zusätzliche Effizienz aus der vorhandenen Hardware herauszuholen.
Im Gegensatz zu Modin strebt Dask keine vollständige Kompatibilität mit der Pandas-API an, sondern entfernt sich von Pandas immer dann, wenn zusätzliche Leistung erforderlich ist.
Dask bietet außerdem weit mehr Funktionen als Vaex oder Modin. Während diese Bibliotheken nur ihre eigene DataFrame-ähnliche Funktionalität anbieten (z. B. als Pandas-Ersatz), kann Dask zur Skalierung jedes Python-Codes verwendet werden und bietet zusätzlich einen Ersatz für Numpy und Scikit-learn an.

Nutze Dask, wenn du große Datensätze skalieren und Compute-Cluster verwenden möchtest.
Nutze Dask nicht, wenn du nicht bereit bist, deine Projekte etwas komplexer zu gestalten.
RAPIDS cuDF
Während die anderen Bibliotheken, die wir uns angesehen haben, RAM und CPUs effektiver nutzen, ist RAPIDS für den Einsatz auf NVIDIA-GPUs ausgelegt. Ähnlich wie Dask bietet RAPIDS eine Reihe von Tools mit Alternativen nicht nur für Pandas, sondern auch für Scikit-Learn.
RAPIDS konzentriert sich auf Data-Science-Anwendungsfälle und soll es Entwicklern ermöglichen, komplette Data-Science-Pipelines auf GPUs laufen zu lassen, anstatt Daten in verschiedenen Phasen zwischen GPUs und CPUs hin und her zu schalten.
Verwende RAPIDS, wenn du Zugriff auf NVIDIA-GPUs hast und diese zur Beschleunigung deiner Python Data Science-Pipelines verwenden möchtest.
Verwende RAPIDS nicht, wenn du keine GPUs zur Verfügung hast.
Plotting and Visualisierung
Incumbent: Matplotlib
Warum Matplotlib beliebt ist: Reife und Flexibilität
Probleme: Code ist oft umfangreich, Standardeinstellungen sind unschön und es eignet sich nicht gut für interaktive Visualisierungen.
Herausforderer: Seaborn, Bokeh, Plotly, Datashader
Matplotlib ist für viele Entwickler die Go-to-Python-Visualisierungsbibliothek. Sie verfügt über eine breite Funktionalität, mit der man so gut wie jede Art von Diagramm erstellen kann und lässt sich gut mit anderen Bibliotheken, wie z. B. Pandas, integrieren.
Die standardmäßig erstellten Diagramme sind jedoch eher unschön und man benötigt dafür mehr Zeilen Code als neuere Visualisierungsbibliotheken. Außerdem wurde Matplotlib hauptsächlich zur Erstellung statischer Bilddateien, wie PNGs, entwickelt. Um Visualisierungen interaktiv zu gestalten oder in Web-Dashboards einzubetten, sollte man sich nach Alternativen umsehen.
Wie lösen andere Bibliotheken diese Probleme?
Es gibt Dutzende von beliebte Python-Visualisierungsbibliotheken. Einen guten Überblick bekommt man mit Jake VanderPlas Vortrag zum Thema, wir decken hier einen Teil davon ab. Diese neueren Bibliotheken bieten schönere Standardeinstellungen, präziseren Code, bessere JavaScript-Integrationen und mehr Effizienz.
Seaborn
Seaborn ist in der Regel die erste Matplotlib-Alternative, an die man sich wendet. Seaborn basiert auf Matplotlib und bietet ansprechendere Standardeinstellungen sowie eine einfachere Syntax für Standardvisualisierungen. Der Nachteil von Seaborn ist vor allem, dass die Möglichkeiten etwas begrenzter sind. Es gibt einige Einstellungen und Diagramme, die man in Matplotlib, aber nicht in Seaborn erstellen kann.
Seaborn wurde jedoch so entwickelt, dass es in Kombination mit Matplotlib verwendet werden kann. Sollte man also an seine Grenzen stoßen, kann man einfach auf Matplotlib-Code zurückzugreifen und etwaige Lücken füllen.
Nutze Seaborn, wenn du nicht-interaktive Plots mit schöner abgestimmten Standardeinstellungen und einfacherem Code als Matplotlib möchtest.
Nutze Seaborn nicht, wenn du interaktive Diagramme oder Dashboards benötigst.
Bokeh
Während Seaborn darauf abzielt, die bestehende Funktionalität von Matplotlib zu vereinfachen, fügt Bokeh neue Funktionen hinzu. Bokeh kann vor allem interaktive Visualisierungen erstellen. Man definiert die Plots in Python und Bokeh erstellt automatisch das erforderliche JavaScript.
Bokeh ist eine gute Wahl, wenn man seine Plots als Teil einer Webanwendung oder eines HTML- und JavaScript-basierten Berichts veröffentlichen möchte.
Nutze Bokeh, wenn du interaktive Diagramme oder Dashboards generieren möchtest.
Nutze Bokeh nicht, wenn du gerne selbst JavaScript schreibst oder nur statische Bilder benötigst.
Plotly
Plotly ähnelt Bokeh darin, dass es interaktive Diagramme erstellt und das erforderliche JavaScript aus Python generiert. Außerdem steckt Plotly hinter Dash, ein Framework, mit dem man komplette Webanwendungen direkt in Python schreiben kann.
Nutze Plotly, wenn du interaktive Diagramme oder Dashboards generieren möchtest.
Nutze Plotly nicht, wenn du gerne selbst JavaScript schreibst oder nur statische Diagramme benötigst.
Datashader
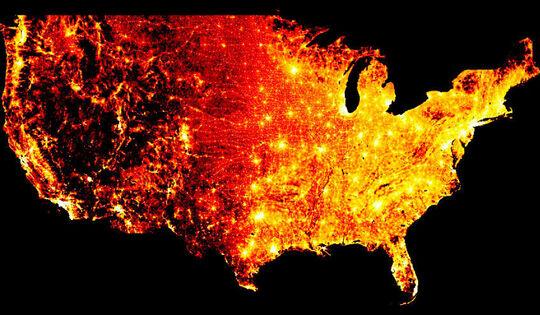
Im Gegensatz zu den anderen genannten Bibliotheken, die sich auf die Erstellung von Plots und Diagramme konzentrieren, konzentriert sich Datashader auf die Visualisierung großer Datensätze. Zum Beispiel wurde das untenstehende Diagramm aus einem riesigen Datensatz mit Datashader generiert, um die Bevölkerungsdichte in den USA darzustellen.
Da Datashader dafür ausgelegt ist, mit großen Datensätzen zu arbeiten, konzentriert es sich weitaus mehr auf Leistung und Effizienz als die anderen Bibliotheken. Es ist jedoch weniger gut geeignet um einfachere Diagramme, wie z. B. Scatterplots, zu erzeugen.
Nutze Datashader, wenn du Diagramme aus wirklich großen Datensätzen oder mit weit mehr als Millionen von Punkten erzeugen möchtest.
Nutze Datashader nicht, wenn du nur Standard-Charts auf kleineren Datensätzen erstellen möchtest.
Fazit
Pandas und Matplotlib sind oft die erste Wahl für Data Scientists und Python-Programmierer. So leistungsfähig und ausgereift diese Bibliotheken auch sein mögen, sie weisen dennoch einige Mängel auf und es gibt gute Alternativen, die diese Mängel beheben.
Welches für dich am besten geeignet ist, hängt von deinem konkreten Problem ab, und man sollte die neueren „Herausforderer“-Bibliotheken eher als Unterstützung der etablierten Bibliotheken sehen und nicht als Konkurrenz.
Artikelfiles und Artikellinks
Link: Data Revenue im Web
(ID:46851117)
