
Comentario de Markus Schmitt, Data Revenue ¿Es hora de reemplazar Matplotlib y Pandas?
23 de septiembre de 2020Autor/Editor: Markus Schmitt/Nico Litzel
Los programadores disfrutan mucho comparando diferentes bibliotecas de software. Tensor Flow vs Pytorch? ¿Vim contra Emacs? ¿Python contra R? Asumiendo una especie de competencia global en la que el software compite por popularidad, Pandas y Matplotlib representan a los jugadores más establecidos en el espacio de ciencia de datos de Python y se encuentran entre las bibliotecas más antiguas y más utilizadas para la visualización y disputa de datos. Sin embargo, dentro de esta competencia también hay competidores interesantes.
Empresas sobre el tema
En el área de disputa de datos, bibliotecas como Dask, Vaex y Modin ofrecen algunas ventajas sobre Pandas, aunque son incluso menos maduras. Del mismo modo, Bokeh y Seaborn (entre muchos otros) compiten con Matplotlib en el rico panorama de visualización de Python porque ofrecen API más simples, configuraciones predeterminadas más agradables y características modernas, como la interactividad.
En este artículo:
Algunas bibliotecas populares de Python destacan y analizan por qué son de interés para los científicos de datos y los desarrolladores de aprendizaje automático;
Compárelos con Matplotlib y Pandas y
Concluye que "competencia" es la forma incorrecta de verlo. Un cuchillo para mantequilla no es mejor ni peor que un cuchillo para pan, simplemente hacen diferentes trabajos. Del mismo modo, generalmente depende de la tarea en cuestión qué herramienta de Python debe usar. Las herramientas a menudo se complementan entre sí.
Disputa de datos
Titular: Pandas
Por qué Pandas es popular: simplicidad, madurez y flexibilidad
Problemas: ineficaz, no escalable y, a menudo, limitado a un solo subproceso.
Desafiantes: Dask, Modin, Vaex y RAPIDS cuDF (comparación detallada)
Los pandas se quejan mucho. Incluso el desarrollador original de Pandas ha escrito críticas mordaces sobre Pandas. Sin embargo, para muchos científicos de datos es una herramienta indispensable que permite flujos de trabajo simples, p. B: para:
Leer datos de varios formatos de archivo, incluidos JSON y CSV;
Cargar datos en objetos de marco de datos;
Manipular datos filtrando, transformando o agregando;
Visualice datos a través de una integración perfecta con Matplotlib.
Sin embargo, debido a que Pandas se creó con un enfoque tan fuerte en la simplicidad y la flexibilidad, tiene un desempeño deficiente en otras áreas, particularmente en términos de eficiencia y escalabilidad para grandes conjuntos de datos.
¿Cómo resuelven estos problemas otras bibliotecas?
Todas las bibliotecas que examinamos como retadoras de pandas intentan preservar la interfaz familiar de pandas al implementar (total o parcialmente) la API de pandas. Al mismo tiempo, resuelven problemas de eficiencia mediante un mejor uso de hardware más potente (procesamiento multinúcleo, procesamiento de GPU o computación en clúster) o algoritmos inteligentes (como la evaluación diferida y el mapeo de memoria).
Modin
Modin es la herramienta más simple de todas y tiene como objetivo proporcionar un reemplazo completo para pandas. Si ya tiene el código de Pandas, puede hacer un progreso significativo ajustando una sola línea.
importar pandas como pd
Reemplacemos con:
importar modin.pandas como pd
Hay algunos preparativos que deben hacerse primero. Primero instala Modin (a través de pip o similar) y luego Dask o Ray, los backends en los que se ejecuta Modin. Entonces todo debería funcionar directamente.
Use Modin si su código existente se basa en gran medida en Pandas y está buscando la manera más fácil de optimizar la ejecución de Pandas.
No utilice Modin si busca un mayor control sobre la escalabilidad o si valora la eficiencia por encima de la facilidad de uso.
Vaex
Al igual que Modin, Vaex implementa parte de la API de Panda y, a menudo, se puede utilizar como alternativa. Sin embargo, a diferencia de Modin, Vaex no busca una compatibilidad total con los pandas. En cambio, Vaex se enfoca principalmente en la exploración y visualización. Con Vaex, puede explorar y visualizar conjuntos de datos en su computadora portátil normal, incluso si son más grandes que la memoria disponible de su computadora. Vaex lo hace posible a través de una combinación de evaluación diferida (realizar cálculos solo cuando los resultados son definitivamente necesarios) y mapeo de memoria (tratar archivos en discos duros como si estuvieran cargados en RAM).
Utilice Vaex cuando desee explorar y visualizar un gran conjunto de datos en hardware normal.
No utilice Vaex si desea una manipulación de datos más sofisticada o escalar a un grupo de servidores.
Oscuro
Aunque Modin se ejecuta en Dask, Dask también proporciona una biblioteca de alto nivel similar a Pandas llamada Dask.Dataframe. Similar a Modin, esta biblioteca implementa muchos de los métodos de Pandas, lo que le permite reemplazar completamente a Pandas en ciertos casos. Al igual que Vaex, Dask usa Lazy Evaluation para extraer eficiencias adicionales del hardware existente.
A diferencia de Modin, Dask no busca la compatibilidad total con la API de Pandas, sino que se aleja de Pandas cuando se requiere un rendimiento adicional.
Dask también ofrece muchas más funciones que Vaex o Modin. Si bien estas bibliotecas solo ofrecen su propia funcionalidad similar a DataFrame (por ejemplo, como reemplazo de Pandas), Dask se puede usar para escalar cualquier código de Python y, además, ofrece un reemplazo para Numpy y Scikit-learn.
título ="¿Es hora de reemplazar matplotlib y pandas?" >
Utilice Dask cuando desee escalar grandes conjuntos de datos y utilizar clústeres de cómputo.
No use Dask a menos que esté dispuesto a agregar algo de complejidad a sus proyectos.
CUDF RÁPIDOS
Mientras que las otras bibliotecas que analizamos hacen un uso más eficiente de la RAM y las CPU, RAPIDS está diseñado para ejecutarse en las GPU de NVIDIA. Similar a Dask, RAPIDS ofrece un conjunto de herramientas con alternativas no solo para pandas sino también para scikit learn.
RAPIDS se centra en los casos de uso de la ciencia de datos y tiene como objetivo permitir que los desarrolladores ejecuten canalizaciones completas de ciencia de datos en GPU en lugar de intercambiar datos entre GPU y CPU en diferentes etapas.
Use RAPIDS si tiene acceso a las GPU de NVIDIA y quiere usarlas para acelerar sus canalizaciones de ciencia de datos de Python.
No use RAPIDS si no tiene GPU disponibles.
Trazado y visualización
Titular: Matplotlib
Por qué Matplotlib es popular: Madurez y flexibilidad
Problemas: el código suele ser voluminoso, la configuración predeterminada es fea y no se presta bien a las visualizaciones interactivas.
Desafiantes: Seaborn, Bokeh, Plotly, Datashader
Matplotlib es la biblioteca de visualización de Python para muchos desarrolladores. Tiene una amplia gama de funciones para crear casi cualquier tipo de gráfico y se integra bien con otras bibliotecas como B. Los pandas se integran.
Sin embargo, los gráficos creados de forma predeterminada son bastante feos y requieren más líneas de código que las bibliotecas de visualización más nuevas. Además, Matplotlib se diseñó principalmente para crear archivos de imágenes estáticas, como PNG. Para hacer que las visualizaciones sean interactivas o para integrarlas en paneles web, se deben buscar alternativas.
¿Cómo resuelven estos problemas otras bibliotecas?
Hay docenas de bibliotecas de visualización de Python populares. Puede obtener una buena descripción general con la charla de Jake VanderPla sobre el tema, cubriremos parte de ella aquí. Estas bibliotecas más nuevas ofrecen mejores valores predeterminados, código más conciso, mejores integraciones de JavaScript y más eficiencia.
Nacido del mar
Seaborn suele ser la primera alternativa a matplotlib a la que recurre la gente. Seaborn se basa en Matplotlib y ofrece configuraciones predeterminadas más agradables y una sintaxis más simple para visualizaciones estándar. La principal desventaja de Seaborn es que las opciones son un poco más limitadas. Hay algunas configuraciones y gráficos que puede crear en Matplotlib pero no en Seaborn.
Sin embargo, Seaborn fue desarrollado para usarse en combinación con Matplotlib. Entonces, si llega a sus límites, simplemente puede usar el código de Matplotlib y completar los espacios en blanco.
Utilice Seaborn cuando desee diagramas no interactivos con valores predeterminados mejor ajustados y un código más simple que matplotlib.
No utilice Seaborn si necesita gráficos o paneles interactivos.
Bokeh
Si bien Seaborn tiene como objetivo simplificar la funcionalidad existente de Matplotlib, Bokeh agrega nuevas características. Sobre todo, Bokeh puede crear visualizaciones interactivas. Usted define las tramas en Python y Bokeh crea automáticamente el JavaScript requerido.
Bokeh es una buena opción cuando desea publicar sus gráficos como parte de una aplicación web o un informe basado en HTML y JavaScript.
Utilice bokeh cuando desee generar gráficos o paneles interactivos.
No utilices bokeh si te gusta escribir tu propio JavaScript o simplemente necesitas imágenes estáticas.
Plotly
Plotly es similar a Bokeh en que crea gráficos interactivos y genera el JavaScript necesario desde Python. Plotly también está detrás de Dash, un marco que le permite escribir aplicaciones web completas directamente en Python.
Utilice Plotly si desea generar gráficos o paneles interactivos.
No utilices Plotly si te gusta escribir JavaScript tú mismo o simplemente necesitas gráficos estáticos.
Sombreador de datos
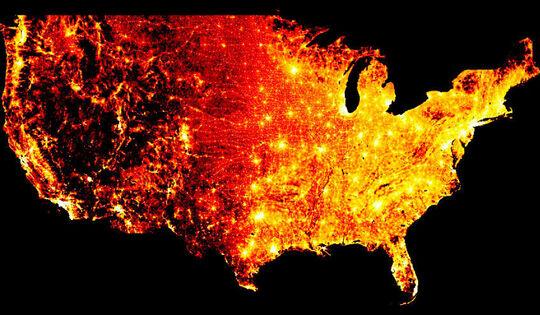
A diferencia de las otras bibliotecas mencionadas que se enfocan en crear diagramas y gráficos, Datashader se enfoca en visualizar grandes conjuntos de datos. Por ejemplo, el siguiente gráfico se generó a partir de un gran conjunto de datos utilizando Datashader para mostrar la densidad de población en los Estados Unidos.
Dado que Datashader está diseñado para trabajar con grandes conjuntos de datos, se enfoca mucho más en el rendimiento y la eficiencia que las otras bibliotecas. Sin embargo, es menos adecuado para mostrar diagramas más simples como B. Diagramas de dispersión para generar.
Utilice Datashader cuando desee crear gráficos a partir de conjuntos de datos realmente grandes o con más de millones de puntos.
No utilice Datashader si solo desea crear gráficos estándar en conjuntos de datos más pequeños.
Conclusión
Pandas y Matplotlib suelen ser la primera opción para los científicos de datos y los programadores de Python. A pesar de lo poderosas y maduras que son estas bibliotecas, todavía tienen algunas deficiencias y existen buenas alternativas que solucionan esas deficiencias.
Cuál es mejor para usted dependerá de su problema específico, y las bibliotecas "desafiantes" más nuevas deben verse como un apoyo a las bibliotecas establecidas en lugar de una competencia.
Archivos de artículos y enlaces a artículos
Enlace: Ingresos de datos en la Web
(ID:46851117)
